Observability
19 Nov 2021Goal
- To share statistics produced by Envoy proxy and Ambassador with Prometheus to generate time-series metrics, and visualize them as dashboards in Grafana
Discussion
Helloworld is getting better and better, while adding more and more components and complexity. This necessitates us to have good visibility into what’s happening in the cluster and in our service. Unfortunately, that’s an area where we seriously lack. Thankfully, our edge stack is capable of producing a wealth of telemetry ripe for consumption.
First step in any monitoring system is to be able to create and track metrics in a time-series data store. This provides both a real-time view into what’s happening at the moment, and also the ability to look back into the recent past to make sense of what might have happened. The raw data is also available for further processing and analytics. A popular option in this space is Prometheus.
Once we generate time-series metrics, we need the ability to query it as well as build rich visualizations and dashboards on top of it. Prometheus has a query language called PromQL and an expression browser, but we will be using Grafana for its extensive dashboarding capabilities. Once we have a way to generate metrics and visualize it, we need to be able to react to specific data points that are critical, via some alerting mechanism. Prometheus also has the ability to configure such alerts, which we will not explore in this post. It deserves a seperate exercise to dig deeper.
Also, we will not be generating our own logs since our service is too simple. We will do it at a later point in time with a better example. For now, we are just focussing on info already produced by our infra and scraped by Prometheus.
Infra
Same old 3 VM instances running on top of Hyper-V.
Stack
Same old helloworld post stack, but we will introduce a package called fastapi-versioning to help with API versioning in FastAPI.
Containerization and Orchestration
- Docker and Kubernetes
API Gateway
- Ambassador Edge Stack, MetalLB
Observability
- Envoy and Ambassador statistics, Prometheus, Grafana
Architecture

Setup
Moar YAML for you, basically. Please remember to kubectl apply since I won’t be mentioning that explicitly. Also, note that a lot of info in Ambassador documentation around this is either outdated or have mistakes. I will try to provide corrections where necessary.
The first point to realize is that Ambassador has a nice endpoint called metrics where all Envoy and Ambassador statistics are available. We are just going to feed that endpoint to Prometheus to scrape and product metrics.
First, let’s expose this endpoint via a Mapping for us to see and for Prometheus to consume.
apiVersion: getambassador.io/v3alpha1
kind: Mapping
metadata:
name: metrics
spec:
hostname: "*"
prefix: /metrics
rewrite: ""
service: localhost:8877
Now, we can see these statistics at:
http://<ambassador-ip-addr>/metrics
Next, we install Prometheus Operator, which is a Kubernetes-native deployment of Prometheus.
kubectl create -f https://github.com/prometheus-operator/prometheus-operator/blob/main/bundle.yaml
Then we need to create some RBACs (role-based access control) for Prometheus. For this, you grab the YAML from https://www.getambassador.io/yaml/monitoring/prometheus-rbac.yaml. The YAML has two references to rbac.authorization.k8s.io/v1beta1. We need to change both to rbac.authorization.k8s.io/v1. Without this, the RBACs won’t be created, and Prometheus won’t work.
Now, we are ready to spin up a service for Prometheus.
apiVersion: v1
kind: Service
metadata:
name: prometheus
spec:
type: ClusterIP
ports:
- name: web
port: 9090
protocol: TCP
targetPort: 9090
selector:
prometheus: prometheus
---
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
ruleSelector:
matchLabels:
app: prometheus-operator
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
app: ambassador
resources:
requests:
memory: 400Mi
The final step for Prometheus is to create a ServiceMonitor. This is how we tell Prometheus where to scrape data from - in our case, the metrics endpoint. Note that the reference to ambassador-admin below has already been created when we installed Ambassador. It just points to the admin service which houses the metrics endpoint as well.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: ambassador-monitor
labels:
app: ambassador
spec:
namespaceSelector:
matchNames:
- ambassador
selector:
matchLabels:
service: ambassador-admin
endpoints:
- port: ambassador-admin
Now, on to Grafana. The YAML is long and I have updated the image version for grafana. It covers the Deployment, Service as well as Mapping for Grafana. You need to ensure that you are setting the right scheme (if you did TLS already, then https), and the right Ambassador IP address or the domain name that you have DNS-mapped to this IP.
kind: Deployment
apiVersion: apps/v1
metadata:
name: grafana
labels:
app: grafana
component: core
spec:
replicas: 1
selector:
matchLabels:
app: grafana
component: core
template:
metadata:
creationTimestamp: null
labels:
app: grafana
component: core
annotations:
sidecar.istio.io/inject: 'false'
spec:
volumes:
- name: data
emptyDir: {}
containers:
- name: grafana
image: 'grafana/grafana:7.5.2'
ports:
- containerPort: 3000
protocol: TCP
env:
- name: GF_SERVER_ROOT_URL
value: :///grafana
- name: GRAFANA_PORT
value: '3000'
- name: GF_AUTH_BASIC_ENABLED
value: 'false'
- name: GF_AUTH_ANONYMOUS_ENABLED
value: 'true'
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_PATHS_DATA
value: /data/grafana
resources:
requests:
cpu: 10m
volumeMounts:
- name: data
mountPath: /data/grafana
readinessProbe:
httpGet:
path: /api/health
port: 3000
scheme: HTTP
timeoutSeconds: 1
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: grafana
spec:
ports:
- port: 80
targetPort: 3000
selector:
app: grafana
component: core
---
apiVersion: getambassador.io/v3alpha1
kind: Mapping
metadata:
name: grafana
spec:
hostname: "*"
prefix: /grafana/
service: grafana
Grafana should be ready now at:
https://<ambassador-ip-addr>/grafana/
The first thing we will do in Grafana is to add a data source. We will select the data source type as Prometheus and add this URL: http://prometheus.default:9090. ‘Save and Test’ and see if it says that the data source is working. Once ready, then we will grab a dashboard created by Ambassador that covers live charting for some basic stats. To do this, we ‘Import’ a dashboard configuration by providing the dashboard id 13758.
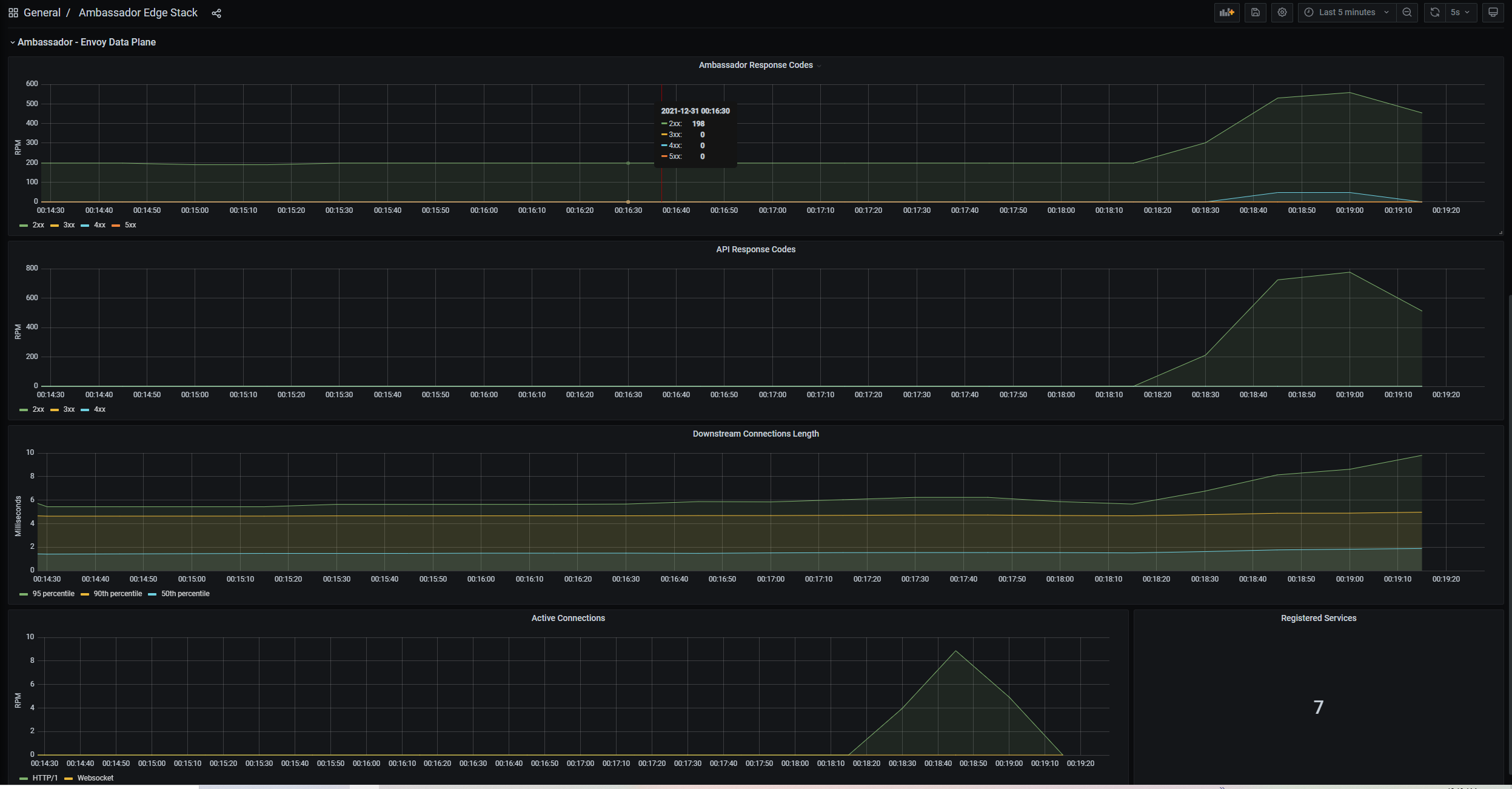
That’s it. Now, we can trigger our service a few times, check the Grafana dashboard, and it should present graphs like:
Code
No code. All config!
Summary
| Tenet | State | Observation |
|---|---|---|
| Observable | Better | Using Ambassador, Prometheus and Grafana, we now have ways to capture, monitor and visualize the various metrics that are relevant in understanding the health and performance of our infrastructure. We can do a lot more, but we have a good foundation. |
In future posts, we will explore alerting, service-level logging and end-to-end tracing, which are key aspects of observability. With this post though, we have arrived at a point where we can review where our helloworld service is now, with respect to the tenets and expectations we set for it back here. We will cover that review in the next post.
